Date: September 8, 2025
Everyone wants to talk to data.
Connect a database. Ask in English. Get answers.
That pitch sells well. It breaks fast.
The Pattern
The AI can see tables. It cannot see meaning.
"What's churn?" looks simple. The query may be clean. The answer can still be wrong.
Churn may exclude seasonal buyers. Enterprise churn may run on a different clock. Finance may count from contract date. Product may count from last activity.
That logic rarely lives in the schema. It lives in docs, formulas, meetings, and memory.
The AI can read the database. It cannot read the business.
Three Layers
Your database holds facts. Your company runs on meaning.
- Facts: what happened
- Meaning: what it counts as
- Implications: what to do next
Most AI tools read facts. They guess at meaning. They miss implications.
The Cost
Every answer has a cost. You pay once or pay forever.
Weekly active users sounds simple. Count uniques over seven days.
Ask it five times. Scan the data five times.
The real answer is boring. Precompute the metric. Store the result. Refresh it on a schedule.
That is infrastructure. That is the work.
Questions Are Workflows
"Why did revenue drop?" is not a query. It is an investigation.
You define the baseline. Segment the drop. Find what changed. Test the cause. Validate the result.
A query returns a number. A workflow earns an answer.
What Works
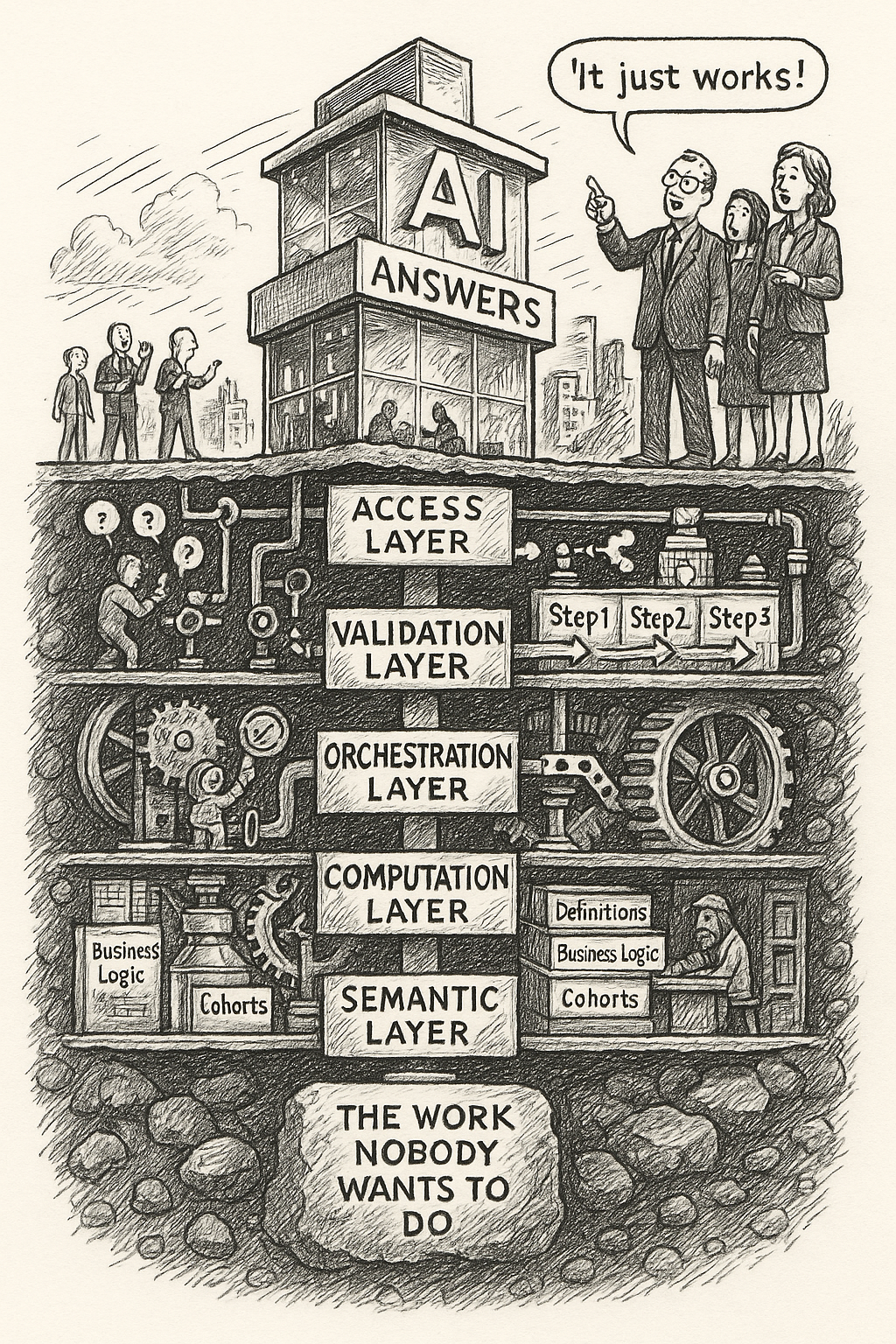
Build five layers:
- Semantic layer: definitions, formulas, assumptions
- Computation layer: materialized metrics and joins
- Orchestration layer: repeatable analysis flows
- Validation layer: checks, reconciliation, lineage
- Access layer: natural language on top
Skip one layer. The failure is predictable.
No semantic layer. Definitions drift.
No computation layer. The system gets slow.
No orchestration layer. Every question starts over.
No validation layer. Wrong answers look right.
The Work
Better AI will help. It will not know your business by reading table names.
The product is not the chatbot. The product is the encoded understanding under it.
The semantic layer is the product. The AI is the interface.
That is what nobody wants to build. That is what everybody needs.